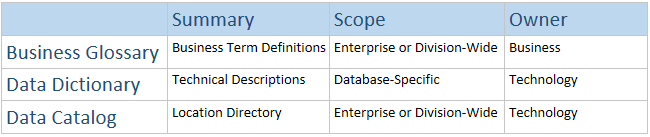
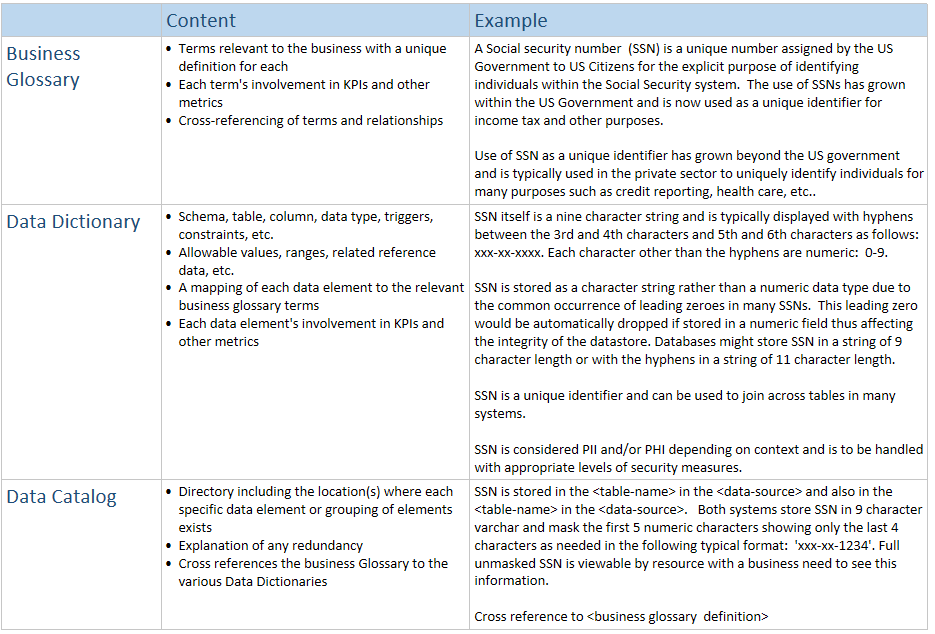
Accelerating Insights: Agile BI through Rapid Prototyping
Dirk Garner
The Delayed Value Dilemma
BI projects are commonly delivered through a waterfall approach wherein each of the primary project phases (analysis, requirements, design, build, test, etc.) are executed sequentially, one after the other, generally resulting in a lengthy delivery cycle of 6-24 months or more. A typical BI deliverable may be integrated/modeled data, reports, dashboards, or visualizations. Project management in the waterfall approach emphasizes delivery of an end-product and adhering to the timeline. This approach requires numerous variables to be considered and accounted for in the timeline, with feedback loops generally only coming into play during QA and UAT. The objective of finding actionable business insight is not typically considered as a time bound objective in the waterfall approach and is not typically a line item in the project plan.
In the waterfall approach, it is not until the delivery phase that the business can begin exploring and mining the data for actionable insight. In other words, the very thing we need from a BI project — actionable insight — is not remotely possible until the very end of the project. (Although, the first business view of the data may happen during the UAT phase, depending on whether live production data is used, versus mocked-up or de-identified data.) From the delivery team’s perspective, the project is completed once the project deploys, but from the business’ perspective the work has just begun at that point. This is clearly a misalignment of objectives among the business and technology. The business is asked to engage heavily at first to define requirements and is then instructed to withdraw while technology builds to meet those requirements. The business is then expected to jump back in for UAT and provide project sign-off before being able to mine the data for potential business value in hopes of finding actionable business insight. And just then, when the business is ready to roll up their sleeves and get to work, the technology team typically ramps down leaving at best a skeleton crew to support the business’ mining efforts. So as a result, the very reason we started the project (the finding of actionable insight) is left with little or no participation and/or support from technology and rarely is there a funded team available to iterate and refine with the business team.
Once the business does get to work in their newly delivered BI playground, they tend to discover that the product that was delivered does not meet their requirements for any number of possible reasons; the requirements documented were not what was actually desired, the business didn’t know what they wanted so long ago, the requirements changed over time, the original need for the BI has passed so it is no longer relevant, etc. It is at this time, after seeing and working in the deliverable that the business is best prepared to provide valuable feedback to technology regarding the requirements, design and deliverable(s). These insights would have been invaluable during the now ended activities of analysis, design, and development, but at this late stage of the project it is unlikely that there is sufficient staff or funding to do anything with that feedback. It is here that the business is most likely to be discouraged and determine that the BI project was a failure, was a futile effort, etc. The business may express their dissatisfaction in any number of ways and the technology team is typically left wondering what went wrong and why the business isn’t happy. Technology will feel that they fulfilled their obligation by building to meet the business requirements. The business will feel that technology doesn’t understand their needs. Worst cases include finger pointing, name calling, or worse; and all of those months of development work are very likely headed to the data scrap dump.
How could we approach BI projects more effectively? How can we realize the value of BI projects quicker? How do we bring the business and technology together to work collaboratively throughout the life of the project and work in synergy through feedback loops?
What about Agile? Agile is a powerful approach to any development project and is expected to infuse the value of feedback loops into projects to evolve the requirements towards the ideal end-state. However, Agile alone can’t solve the data-specific problems encountered in BI projects.
Defining the “Real” Deliverable
Just as the deliverable in the waterfall example above is clearly defined, albeit somewhat ineffective, in Agile BI we should define the deliverable to be the value the business gains from finding actionable insight discovered in the data. In other words, the objective of a BI project is not to build a data model, report or dashboard but rather to derive business value in the form of actionable business insight mined from the data, report or dashboard. This shift in objective definition causes us to view expectations and execution approach from different angles and in different contexts. Using this shifted approach; technology can now march alongside the business towards the common goal of providing opportunities to find actionable insight. This is a completely different mission from developing code to meet requirements by specified due dates. With this Agile BI approach there are still dates by which certain benchmarks are expected to be met, but the emphasis is now primarily on two things: refining business requirements and providing opportunities for the business to discover actionable insight.
Providing Opportunities – Rapid Prototyping
The key is to allow the business to have access to the evolving product as it is being developed and obtain feedback incrementally to evolve and shape the deliverable as it is being built. Employing the principles of rapid prototyping is an excellent approach to meeting this core need. The idea of rapid prototyping is to generate a prototype as quickly as possible in tandem with the business partner’s ability to articulate requirements. Requirements do not need to be complete; in fact it is better to begin prototyping with a few basic requirements. And, after refining those first few requirements, move on to layer in new requirements, and so on. There does not need to be a predefined order to layering in requirements. It may feel disorganized. It may even feel sloppy. But in practice, the refining of requirements happens much quicker with this approach. Also, since reviews are done targeting small areas of change with greater attention to detail, a higher quality of requirements can be expected.
At first, the idea is to get the prototype in front of the business as rapidly as possible with little concern to quality, completeness, or correctness. Those will all come in future iterations. The sole purpose of the initial prototypes is to coalesce all project participants to a common understanding of what is being pursued. The visual representation of this common understanding; whether it is a report, dashboard, or data model, is then subsequently revised, reviewed, and so on.
The less time technology spends on building each prototype, the less time is potentially lost and the less work is potentially thrown away. So in light of that, efforts should be focused on making small changes, gaining feedback, making more small changes, etc. This progressively increases the quality and completeness of the requirements faster than trying to imagine the entire finished product at the outset without any manner to visualize the result or sort through various ideas. For this reason, short cycles work best since the output is reviewed after a smaller number of changes have been made; those changes get a more thorough review by the business, and based on the feedback, quicker remediation efforts for technology enable the next prototype to be available sooner so the cycle repeats.
It is important to emphasize that the feedback loops are safe zones for discussing how far or how close we are to what is needed. Successful rapid prototyping critically needs honest, direct, and quick feedback. Fostering a culture based on principles of collaborative partnerships helps in abundance to establishing friendly and safe zones to gain the honest direct feedback. The only bad feedback in this case is that which is not shared. Care must be taken to manage expectations, feelings, drive, and motivation here to ensure that everyone is expecting both positive and negative feedback and that it is a good thing and will help get to the end state faster.
There are many reasons that rapid prototyping works well to extract and refine requirements. Among those reasons are that it is generally more effective to “tease” out ideas and thoughts than it is to expect someone to be able to list out all of the things they can think of. Prototyping does just that. Having an example at hand, either literally or figuratively, sparks memories, thoughts and ideas that may not be considered without the mental prompting the prototype provides.
Getting to Actionable Insight – Progressively Increasing Value
There is a natural progression to the feedback cycles that can be expected. At first, the feedback from the business is likely to be highly critical and will point out all of things that are incorrect about the prototype. There will be little or no “good” or “usable” parts of the model, and there will many suggestions of what “should” be. But, as the iterations proceed, there is a clear progression that comes to pass.
As requirements become more complete and refined, each new prototype improves in quality, completeness and correctness, and some or all defining characteristics of the underlying data model become clear: data granularity, KPI definition, and the schema approach. During this progression, the team will want to layer in a new objective in each subsequent prototype. This new layer should be a deliberate target of completing an area or areas of the desired end product, whether it is a report, dashboard, data model, or visualization. The targeting approach should be discussed and planned collaboratively so as to maximize the opportunities to find actionable business insight within the completed area(s). For example, if the end deliverable is an integrated model of data to be mined by the business end user, you may choose to complete the model in an area represented by a table or group of tables for which the business has the most curiosity, has the biggest problem, etc. Technology and architectural considerations can also be determining factors regarding which parts of the final deliverable are candidates to be finished independently from other components of the whole.
This approach enables the opportunity for having two distinct feedback loops. The first is the one described above in which technology issues prototypes and the business, most commonly a business analyst, reviews and provides feedback to technology. The focus of this loop is on establishing and refining the requirements of the end product and is the typical feedback loop involved in rapid prototyping. The second feedback loop is where the first opportunities to find actionable business insight arise. The second loop can begin once part of the final deliverable is completed and ready for the business. There are two significant differences in the second feedback loop as compared to the first. The first difference is the introduction of the end business user who acts as reviewer and feedback provider. In the second cycle, the business analyst who has been participating as reviewer and feedback provider to technology is now also in the role of feedback collector for the end business consumer. A product manager may also participate in this second feedback loop as a process and subject expert and also as a protocol shepherd who can manage expectations.
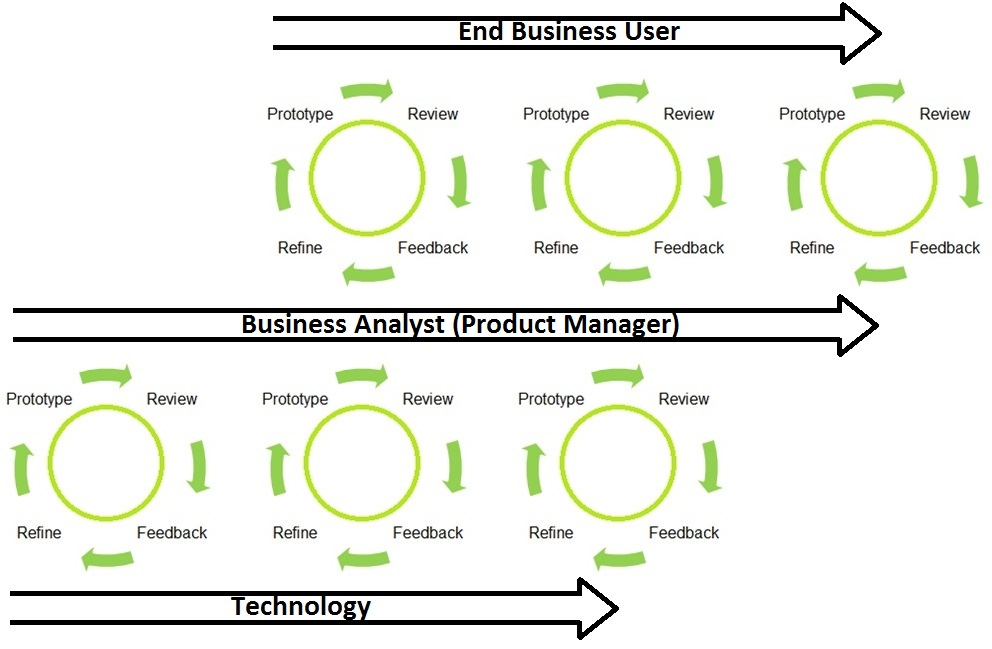
Figure 1. Prototype Feedback Loops
The roles in this second feedback loop are shifted closer to the business. In fact the primary role is that of the business end user, which may be a report consumer, data scientist, data miner, etc. This end business consumer begins reviewing and analyzing the data provided in the finished components of the end deliverable but not the whole product. Parts of the whole product are still under development and are not ready for this business-ready analysis. Care must be taken to clearly demarcate and socialize what is and what isn’t considered business-ready. The business end-user can review, analyze, test, mine, etc. the partially delivered product. Ideally, these opportunities to see the product evolve will provide opportunities for the end user to find relevant insights.
This double feedback loop helps further refine requirements, course-corrections if needed, and commences opportunities to find actionable business insight. Using this approach, insights can be mined simultaneously as the end deliverable continues to evolve. This is how we bring about business value sooner in the BI process.
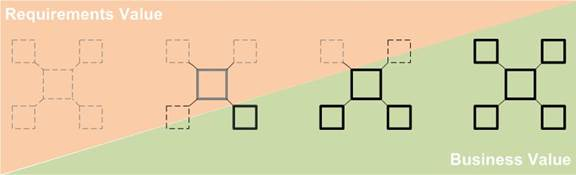
Figure 2. The Progressive Transition of Value in Agile BI with Rapid Prototyping
In the diagram above, the orange triangle represents the progressively increasing completeness and quality of requirements and therefore the decreasing time and effort spent during each feedback loop. The green triangle represents the progression of the evolving completeness of the end product and growing number of opportunities for finding actionable business insight.
When Are We Done?
Teams can be confused about what ‘done’ means using this approach. After all, there are no time bound deliverables so how do we know when we are done? The feedback loops, or iterations, can continue until a specified goal is obtained. Specific goals might be: a report or dashboard is complete, data from disparate data sources has been cleansed, transformed and integrated into a common data model for mining, a target amount of business value has been obtained, funding runs out, time runs out, or the team can agree to proceed until they feel that there is no further value expected remaining in the specific area being researched, or until principles of diminishing returns no longer justify further effort.
Productionalization
In cases where the business has found sufficient ROI and value from the efforts, there may not be anything needed to be built in a robust, stable ‘productionalized’ manner. Thus, all of the prototyping in the iterations can be performed more rapidly with a wireframe, straw man approach without spending time or effort on making it production-ready.
In cases where business objectives warrant the productionalization of reproducible ETLs, reports, dashboards, etc., a parallel planning effort is recommended. This planning, and subsequent development effort, is likely to be more protracted than the feedback loop cycles but is necessary to allow sufficient time to productionalize supporting architectural components. The planning and subsequent build can and should run in parallel to the feedback loops so as not to impeded progress or slow down the feedback cycles. Separate technology teams could be used, but threading the work through the same team provides the highest degree of continuity and the best results. This effort should focus on building what will ultimately become the fault-tolerant rugged product that can be relied upon day after day and should incorporate scalable architectural principles as appropriate. The use of a robust data virtualization platform can be of great value and can streamline this process by acting as not only the prototype but also through the use of caching and automating ETL work it can help deliver the final product will very little additional effort.
An example of an evolution from a raw prototype to final production-quality deliverable follows: Delivering data rapidly and with agility can be as simple as hard coding data in the presentation layer for initial prototypes. This might be mocked up data, screen shots, even whiteboard drawings. As the process progresses, you might pull the data from a service in which the data is hard coded within the service. Next step might be to pull data from a service that consumes data from a database in which the data is mocked up, manually entered, or manually integrated. And finally, as requirements become known, and productionalization is imminent, complete the end to end architectural and development approach and delivery process. The guiding principle is to evolve your architectural and development approaches as the requirements of the end product evolve so as not to generate throw away work, accumulate technical debt and to ensure best alignment of solution architecture to the end deliverable.
Adoption Challenges
Any new process, procedure, language, etc. can be expected to be met with anxiety, skepticism, discomfort, reluctance, resistance, or sometimes outright defiance. Socializing the value to the organization, the benefits to the team, and the benefits to the individuals are key factors to driving adoption.
Benefits, value, and drivers for the use of Agile BI with Rapid Prototyping:
-Better quality requirements
-Quicker establishing of requirements
-Quicker valuable insights
-Quicker ROI
-Increased business partner satisfaction
-Less long term throw away work
-Better team collaboration
Establishing a positive message emphasizing the benefits of the process and subsequently socializing that message consistently, thoroughly, and repeatedly is essential to driving adoption. Coaching a team new to rapid prototyping will require consistent attention and focus at least up until the point at which the team has self-organized and is driving forward independently. As new team members join projects, training, on-boarding, and re-socialization will be necessary to keep the culture and dynamics of the team focused on the agile/rapid paradigm. This on-boarding can and generally is performed by the existing team members.
The technology team may have and may express concerns such as a fear of a new, unknown, unproven approach, or their dissatisfaction with the idea of throwing away (prototype) work, or their discomfort of delivering partially completed work, or the difficulties in providing data with agility and in a rapidly, evolving manner. Producing non-productionalizable, non-sustainable, and hard coded deliverables can cause discomfort and confusion to technology teams. Emphasizing the benefits of using the agile/rapid approach and that a collaborative partnership jointly focused on finding actionable business insight is the best way to serve the business objectives helps foster the best perspectives in these regards and helps brings teams into alignment and build synergy.
Data specific challenges in rapid prototyping may also impede technology team’s willingness to adopt the approach. Leveraging agile/rapid approaches to data delivery can be very effective and assists in delivering prototypes to the business rapidly without generating a lot of wasted effort or creating technical debt. Rapid data delivery can be accomplished much like the approach to rapid code development or rapid GUI development. The objective is to deliver the minimum data required to get the point across with as little effort as possible knowing that there is likelihood that the feedback collected may change directions entirely. For this reason it is not prudent to spend much or any time creating data delivery solutions. Eventually, there may be the need to productionalize the end deliverable. But until we know what data the business wants, how they want to see it, how data will need to be modeled, technology teams should only architect and build minimal solutions, as needed, to deliver the prototypes. In this manner, the architecture evolves incrementally, with agility, and with flexibility to ensure best overall alignment with the end deliverable.
Project Managers might feel a little lost in Agile BI without the familiar concrete benchmarks to drive the team by and towards. The project manager’s deliverables in Agile BI are abundant but very different from those in a waterfall approach. The project manager will be establishing and maintaining the iteration schedule by which the technology team builds and delivers prototypes and the business analyst reviews and provides feedback thus launching another feedback cycle. Additionally, the second feedback loop will cause the project manager to duplicate efforts in tracking and keeping the two feedback loop teams on track and on schedule. Added to these responsibilities is process socialization and expectation management specific to the use of Agile BI and rapid prototyping. The project manager will also be responsible for shepherding the development teams, who are likely to be less heads-down performing development work and will be more focused on capturing and implementing innovative ideas.
In adopting Agile BI and Rapid Prototyping principles, business analysts may struggle with the idea that they need to review something known to be imperfect. Just as with the technology team, fostering the collaborative partnering environment with repeated emphasis on the benefits of using the agile/rapid approach will help drive adoption and set expectations and perspectives.
The end business consumer’s expectations and understanding can determine whether the use of Agile BI will or will not be successful. The end user is likely to be confused by what technology is doing and why. Further, it is unlikely that they would be able to accept the idea that there is value in reviewing anything without complete and accurate data. It is for this reason that the business analyst participates in the primary feedback loop on the business’ behalf. The challenges of engaging the business with rough prototypes seem far too great to overcome and tend to lead to unnecessary churn instead of productive feedback loops.
A challenge that is worth addressing is to introduce the end business user to the partially completed end product in the second feedback loop. There will still be confusion and pushback. But having part of their deliverable much earlier than expected and being able to begin to working within that deliverable to find valuable insight should help replace the confusion and resistance with motivation and engagement. It is best that the business analyst and/or product manager, shepherd the end business user through the process of working with a partially completed deliverable. Expectations, guidelines, training, and edification are all likely to need consistent, repeated socialization to avoid confusion and ensure the most effective use of the deliverable.
Care should be taken in how the end business user is introduced to the partially completed deliverable. A broad landscape view of the evolving end deliverable is helpful to set context of where and how this partially completed deliverable fits into the whole that continues to evolve. Here is where a product manager role could be of most value. The product manager can tie all of the components to the broader whole of the end deliverable and also map the whole to the components and most importantly to the primary objective of finding actionable business insight.
Predicting how well or how poorly your technology and business teams may acclimate to agile and rapid is difficult. One bad apple can bring this approach to a screeching stop and experience has shown that it may be necessary to swap out role players who were unwilling or unable to transition from a waterfall to an agile/rapid approach. In my experience however, once teams have participated in an agile/rapid project and have personally realized the benefits, they are not only ready to participate again but can and do help evangelize and edify team members who are new to the concept.
When to Use Agile BI with Rapid Prototyping
This Agile BI with Rapid Prototyping approach is most effective when used in exploration and discovery projects where it is typical to have a need to acclimate to and maneuver within unfamiliar and frequently undocumented data. It also works exceptionally well for projects involving GUI representations such as a report, dashboard, or visualization. Beyond that, Agile BI with Rapid Prototyping will add value to any project through the acceleration of requirements gathering and the improvement in quality of the requirements.
For projects in which the business begins with a firm understanding of the requirements at the outset, rapid prototyping will have a shorter role in requirements refinement and may not be required at all. Even in these cases, the principles of breaking down the work and delivering through an evolving architecture can provide the opportunity for incremental reviews of progress to facilitate feedback loops, course corrections, and in general help keep projects on track and teams aligned.
In smaller projects, and especially in discovery projects, iterations should be kept short: one or two weeks at the most. In larger efforts, longer iterations are likely to be required especially once the requirements are complete or nearly complete and the heavy lifting of building out infrastructure ensues. Larger projects require longer architectural build time which may necessitate longer iterations providing more time in between releasable prototypes. Incrementally releasing prototypes is still essential to keeping the business engaged, to constantly reconfirm direction and requirements, and continue to provide new and fresher opportunities to find actionable business insight. Also, in smaller initiatives, it is possible for a single resource to serve multiple roles. An example of this might be a Data Architect serving as both Data Modeler and Systems Analyst as well. This in itself has an accelerating effect and can reduce cycle length for prototype releases.
Summary
With the use Agile BI through Rapid Prototyping in appropriate projects, I have observed the highest degrees of business partner’s engagement, satisfaction, and success ratings as compared to any other manner of project delivery.
The following focus points will help maximize success when using this approach:
-Define the objective as “to provide opportunities for the business to discover actionable insight”
-Align teams towards this common goal
-Embrace and support safe-zone feedback loops
-Deliver visual representations of progress (prototypes) in short cycles
-Define and build supporting architecture incrementally as requirements are refined
-Persevere through adoption challenges — it’s worth it
-Increase or decrease emphasis on prototyping depending on the maturity of the requirements
Dirk Garner has a broad technology background spanning 20+ years in data and software engineering and leadership roles including 10+ years as a consultant, focusing on BI, software development, networking, and operational support. He has previously launched and ran a software and systems consulting services company for 10 years and has recently launched a data strategy and full stack development firm. Dirk can be contacted via email:
dirkgarner@garnerconsulting.com or through LinkedIn:
www.linkedin.com/in/dirkgarner. Please refer to
http://www.garnerconsulting.com for more information.